PostgreSQL索引(6) – SP-GiST
本文翻译自Egor Rogov的英文博客,且已征得Egor Rogov的同意。译者做了少量修改。
审校:纪昀红,中国人民大学信息学院在读博士生。
在前面几篇文章中,我们讨论了通用索引引擎、AM的接口和三种AM(Hash索引、B-tree索引、GiST索引)。这篇文章将介绍SP-GiST索引。
首先,介绍一个这个名字。GiST暗示着它和GiST索引有一些类似。它们都是通用搜索树,提供了一个框架用来创建不同的索引类型。
SP表示空间分割(space partitioning)。这里的空间,就是我们平时所成的空间,例如,它可以是一个二维的平面。但是,我们将会看到它可以表示任意搜索空间。
SP-GiST适合可以被递归分割成互不相交区域的空间。这类空间包括:四叉树(quadtrees)、K-D tree、基数树(radix trees)等。
1. 结构
SP-GiST的思想就是把值域划分成互不相交的子域,并且这些子域可以继续被分割。使用这样的分割方式,会导致树不平衡(不像B-tree和常规的GiST索引)。
不相交的特点,使得算法在插入和搜索时的决策过程变得简单。另一方面,这也导致树的平衡度降低。例如,四叉树的一个节点通常包含4个子节点(不像B-tree那样可以包含几百个)并且树比较深。这种树的结构比较适合内存,但是树被存在磁盘上,因此,为了减少IO操作,节点需要被打包存在页面中。打包其实很难高效的完成。而且,因为不同节点的深度不同,所以在树中查找不同的值,代价并不相同。
和GiST一样,SP-GiST也处理了底层的任务(并发控制、日志、搜索框架),并且提供了一个简单的接口为添加新的数据类型和新的分割算法提供支持。
SP-GiST的非叶子节点存储了指向孩子节点的指针;可以为每个指针指定一个标签。非叶子节点可以存储一个称为前缀的值。事实上,这个值不一定是一个前缀;它可以是任意一个所有孩子节点都满足的谓词。
SP-GiST的叶子节点存储了索引类型的一个值,和一个指向基表的TID。索引数据本身(搜索key)可以被用作这个值,但这不是必须的:可以用一个更短的值。
而且,叶子节点可以被分组成list。所以,非叶子节点不但可以指向一个值,而且可以指向一个链表。
注意,叶子节点中的前缀、标签、值都有他们互相独立的数据类型。
和GiST索引一样,定义查询的主要函数就是一致性函数。处理每个节点时都会调用这个函数,这个函数返回与搜索谓词(indexed-field operator expression)一致的孩子节点的集合。对叶子节点来说,这个一致性函数决定节点中的索引值是否满足搜索条件。
查询从根节点开始。一致性函数可以找出需要访问的孩子节点。对找到的节点重复这个过程。使用深度优先搜索。
在物理层面,索引节点被打包到页面中,使得IO更高效。值得注意的是,一个页面要么存放非叶子节点,要么存储叶子节点,不能同时存储二者。
2. 示例:四叉树
四叉树用来索引平面上的点。其中一个方法就是:使用一个中心点把区域划分成4个子区域(象限)。树中分支的深度与相应象限中点的密度相关。
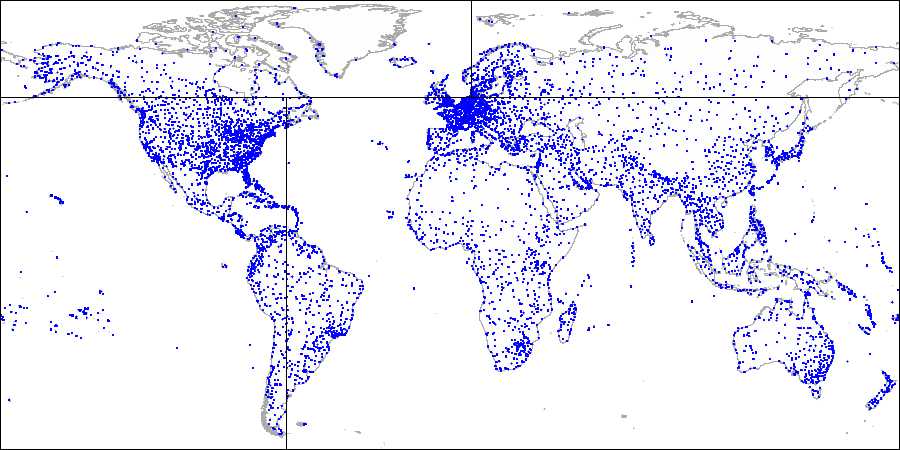
Demo数据库加上openflights.org的数据后,画出的图片如下。后文中,我们把经度和维度换成point。
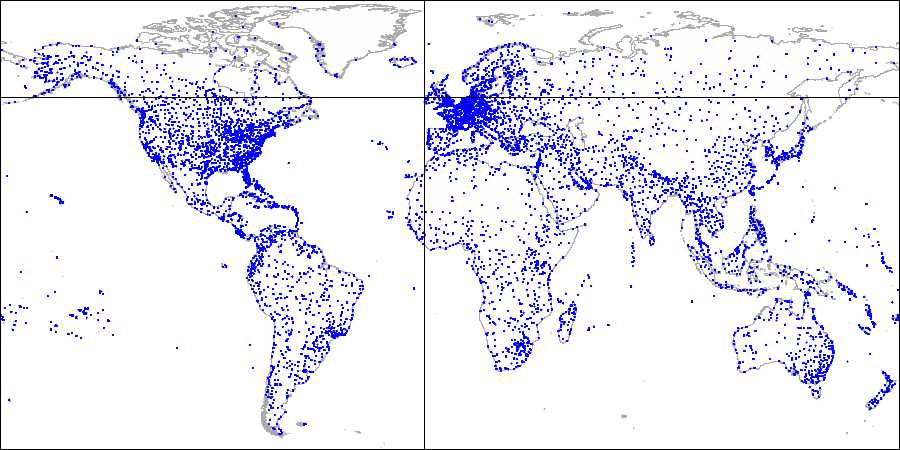
首先,把平面划分成4个象限
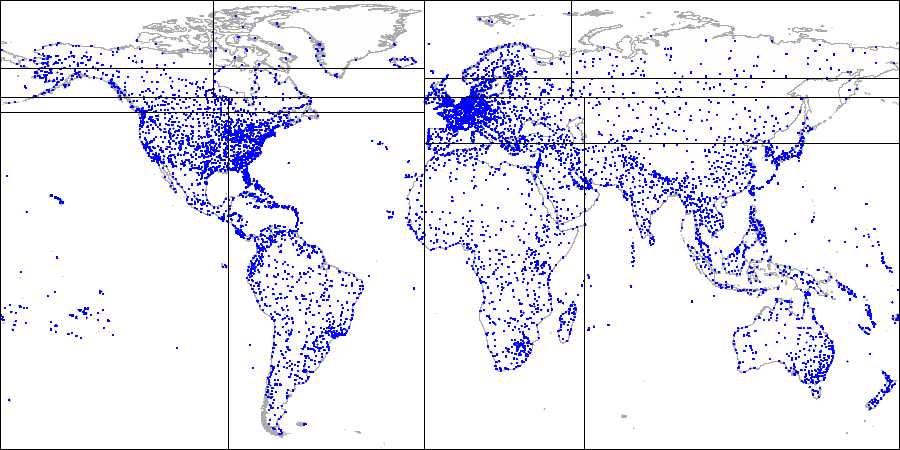
然后,对每个象限继续划分
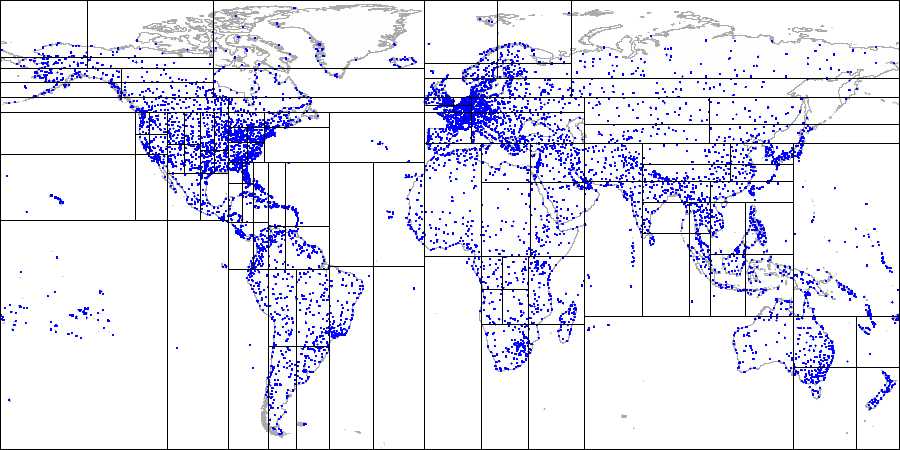
直到得到最后的划分
我们继续讨论上篇文章中那个简单示例的一些细节。划分情况可能是这样:
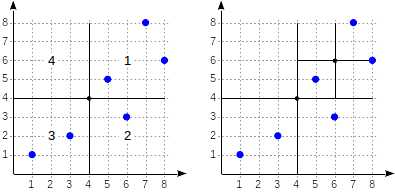
象限的编号在左边的图片中。为了直观,我们按照相同的顺序从左到右依次存放孩子节点。索引可能像下图一样存放。每个非叶子节点最多存放4个孩子节点。每个指针可以用象限的编号表示。在真正的实现中并不需要标签,直接使用数组的下标更加方便。
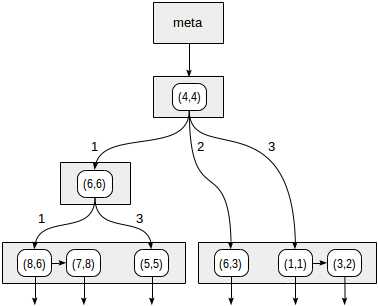
在象限边界上的点属于编号较小的象限。
create table points(p point);
insert into points(p) values
(point '(1,1)'), (point '(3,2)'), (point '(6,3)'),
(point '(5,5)'), (point '(7,8)'), (point '(8,6)');
create index points_quad_idx on points using spgist(p);
这个例子中,默认使用quad_point_ops操作符类,它包含下列操作符:
select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'quad_point_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'spgist'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------+--------------
<<(point,point) | 1 strictly left
>>(point,point) | 5 strictly right
~=(point,point) | 6 coincides
<^(point,point) | 10 strictly below
>^(point,point) | 11 strictly above
<@(point,box) | 8 contained in rectangle
(6 rows)
例如,我们研究select * from points where p >^ point ‘(2,7)’的执行过程(找出在(2,7)上面的点)。
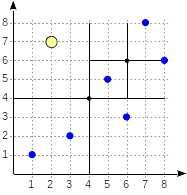
我们从根节点开始,使用一致性函数确定需要搜索哪些孩子节点。对操作符>^来说,这个函数把(2,7)和中心点(4,4)比较,选出符合条件的第一、四象限。
对与第一象限关联的节点,我们继续使用一致性函数。中心点是(6,6),接着再去遍历第一、四象限。
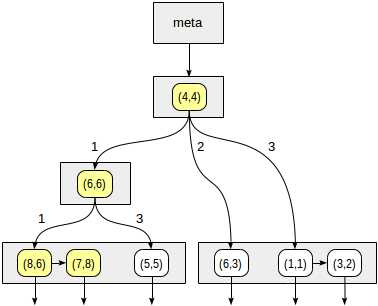
叶子节点中的(8,6) and (7,8)属于第一象限,只有(7,8)满足条件。第四象限代表的内容为空。
非叶子节点(4,4)指向的第四象限也为空,因此搜索过程结束。
set enable_seqscan = off;
explain (costs off) select * from points where p >^ point '(2,7)';
QUERY PLAN
------------------------------------------------
Index Only Scan using points_quad_idx on points
Index Cond: (p >^ '(2,7)'::point)
(2 rows)
内部结构
我们可以继续使用gevel插件探索SP-GiST的内部结构。不幸的是gevel插件与最新的PG不兼容。
例如,demo数据库中展示世界地图的例子。
create index airports_coordinates_quad_idx on airports_ml using spgist(coordinates);
索引的一些统计信息:
select * from spgist_stats('airports_coordinates_quad_idx');
spgist_stats
----------------------------------
totalPages: 33 +
deletedPages: 0 +
innerPages: 3 +
leafPages: 30 +
emptyPages: 2 +
usedSpace: 201.53 kbytes+
usedInnerSpace: 2.17 kbytes +
usedLeafSpace: 199.36 kbytes+
freeSpace: 61.44 kbytes +
fillRatio: 76.64% +
leafTuples: 5993 +
innerTuples: 37 +
innerAllTheSame: 0 +
leafPlaceholders: 725 +
innerPlaceholders: 0 +
leafRedirects: 0 +
innerRedirects: 0
(1 row)
然后,输出树本身:
select tid, n, level, tid_ptr, prefix, leaf_value
from spgist_print('airports_coordinates_quad_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix point, -- prefix type
node_label int, -- label type (unused here)
leaf_value point -- list value type
)
order by tid, n;
tid | n | level | tid_ptr | prefix | leaf_value
---------+---+-------+---------+------------------+------------------
(1,1) | 0 | 1 | (5,3) | (-10.220,53.588) |
(1,1) | 1 | 1 | (5,2) | (-10.220,53.588) |
(1,1) | 2 | 1 | (5,1) | (-10.220,53.588) |
(1,1) | 3 | 1 | (5,14) | (-10.220,53.588) |
(3,68) | | 3 | | | (86.107,55.270)
(3,70) | | 3 | | | (129.771,62.093)
(3,85) | | 4 | | | (57.684,-20.430)
(3,122) | | 4 | | | (107.438,51.808)
(3,154) | | 3 | | | (-51.678,64.191)
(5,1) | 0 | 2 | (24,27) | (-88.680,48.638) |
(5,1) | 1 | 2 | (5,7) | (-88.680,48.638) |
...
spgist_print没有输出所有叶子节点的值,只输出了列表中的第一个。因此,只输出了树的结构,而不是所有的内容。
3. 示例:k-dimensional trees
仍然使用上面的示例,我们还可以使用另外一种方式分割空间。
让我们使用第一个被索引的点水平画一条直线。它将平面分成上下两个部分。第二点属于其中一个部分,使用这个点垂直画一条直线,又可以将这个部分划分成左右两部分。依此类推,继续使用后面的点横竖画线。
所有内部节点都包含2个孩子节点。两个指针要么都指向下一层的叶子节点,要么都指向孩子节点。
这个方法可以很容易地划分k维空间,因此也被称为k-D tree。
展示机场示例的划分过程:
首先将平面划分成上下两部分
把每个部分继续划分成左右两部分
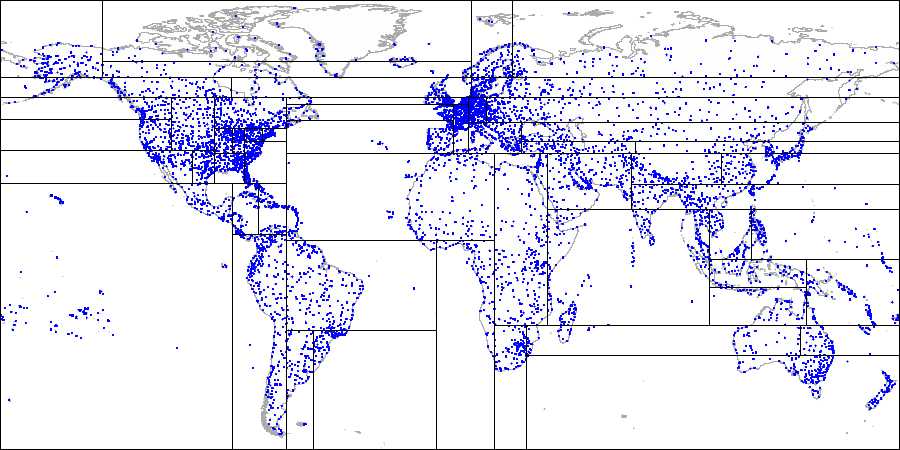
直到得到最终的划分
为了使用这样的划分方式,我们需要在创建索引时显式的指定kd_point_ops操作符类。
create index points_kd_idx on points using spgist(p kd_point_ops);
这个操作符类与默认的quad_point_ops操作符类包含相同的操作符。
内部结构
当我们查看这棵树的内部结构,我们需要考虑到,这个场景下的前缀是一维坐标,而不是一个点。
select tid, n, level, tid_ptr, prefix, leaf_value
from spgist_print('airports_coordinates_kd_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix float, -- prefix type
node_label int, -- label type (unused here)
leaf_value point -- list node type
)
order by tid, n;
tid | n | level | tid_ptr | prefix | leaf_value
---------+---+-------+---------+------------+------------------
(1,1) | 0 | 1 | (5,1) | 53.740 |
(1,1) | 1 | 1 | (5,4) | 53.740 |
(3,113) | | 6 | | | (-7.277,62.064)
(3,114) | | 6 | | | (-85.033,73.006)
(5,1) | 0 | 2 | (5,12) | -65.449 |
(5,1) | 1 | 2 | (5,2) | -65.449 |
(5,2) | 0 | 3 | (5,6) | 35.624 |
(5,2) | 1 | 3 | (5,3) | 35.624 |
...
4. 示例:radix tree
我们还可以使用SP-GiST实现字符串的基数树。基数树的思想是,字符串不是全部存储在叶子节点,而是把从根到此叶子节点的值拼接起来。
假如,我们要存储这几个URL:postgrespro.ru、postgrespro.com、postgresql.org和planet.postgresql.org。
create table sites(url text);
insert into sites values ('postgrespro.ru'),('postgrespro.com'),('postgresql.org'),('planet.postgresql.org');
create index on sites using spgist(url);
树的样子如下所示:
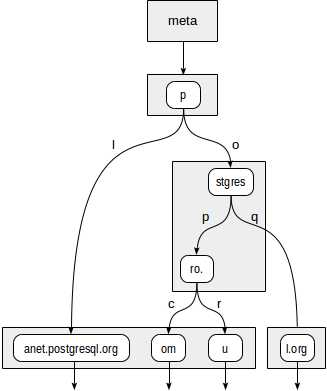
非叶子节点存储了它孩子节点的公共前缀。例如节点stgres的所有孩子节点都以p + o + stgres开头。
与四叉树不同的是,指向孩子节点的指针包含一个额外的标签(精确的说是两个字节,这不重要)。
text_ops操作符类支持B-tree类型的操作符:相等、大于和小于。
select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'text_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'spgist'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------+--------------
~<~(text,text) | 1
~<=~(text,text) | 2
=(text,text) | 3
~>=~(text,text) | 4
~>~(text,text) | 5
<(text,text) | 11
<=(text,text) | 12
>=(text,text) | 14
>(text,text) | 15
(9 rows)
包含波浪号的操作符处理的是字节而不是字符。
有时候,使用基数树的表示方式会比B-tree更紧凑,因为没有存储所有的值,而是在搜索的时候构造出来。
考虑这个查询
select * from sites where url like 'postgresp%ru'
它可以使用索引:
explain (costs off) select * from sites where url like 'postgresp%ru';
QUERY PLAN
------------------------------------------------------------------------------
Index Only Scan using sites_url_idx on sites
Index Cond: ((url ~>=~ 'postgresp'::text) AND (url ~<~ 'postgresq'::text))
Filter: (url ~~ 'postgresp%ru'::text)
(3 rows)
实际上使用索引找出postgresp和postgresq之间的值 (Index Cond),再过滤出符合条件的值(Filter)。
首先,一致性函数必须决定出从根节点p下降到哪个孩子节点。无需下降到p+l,只需要下降到 p + o + stgres 。
以此类推,下降到叶子节点。
内部结构
观察内部结构时,需要考虑数据类型:
select * from spgist_print('sites_url_idx') as t(
tid tid,
allthesame bool,
n int,
level int,
tid_ptr tid,
prefix text, -- prefix type
node_label smallint, -- label type
leaf_value text -- leaf node type
)
order by tid, n;
5. Properties
首先看AM层面的属性(查询见本系列文章的第二篇)
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
spgist | can_order | f
spgist | can_unique | f
spgist | can_multi_col | f
spgist | can_exclude | t
SP-GiST不支持排序、唯一索引和多列。但是支持排它约束。
具体索引层面的属性:
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | t
bitmap_scan | t
backward_scan | f
和GiST的不同的是,它不支持clustering。
最后看列层面的属性:
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | t
search_array | f
search_nulls | t
不支持排序,本文中PG的版本不支持k-NN查询,但是最新版的PG已经支持。
SP-GiST can be used for index-only scan, at least for the discussed operator classes. As we have seen, in some instances, indexed values are explicitly stored in leaf nodes, while in the other ones, the values are reconstructed part by part during the tree descent.
SP-GiST可以被用作Index Only Scan,至少对已经讨论过的操作符如此。在有些情况下,索引的值被存储在叶子节点中,在有些场景下,这些值是在下降过程中被构造出来的。
6. NULL值
为了简单起见,我们还没有讨论NULL值。很明显,它支持NULL:
explain (costs off)
select * from sites where url is null;
QUERY PLAN
----------------------------------------------
Index Only Scan using sites_url_idx on sites
Index Cond: (url IS NULL)
(2 rows)
但是,NULL值被存储在一个单独的区域。spgist操作符类中的所有操作符都必须是严格的,也就是说任何参数为NULL,这些操作符必须返回NULL。GiST索引保证不把NULL值传给这些操作符。
7. 其它数据类型
box_ops操作符类为矩形提供了四叉树的功能。每个被表示成四维空间中的一个点,空间共有16个象限。这种类型的索引在性能上大大好于GiST。因为在GiST索引中不可能在相交的物体之间划清边界,但是对4维空间中的点来说,就不存在这个问题。
range_ops为区间提供了四叉树的功能。一个区间被表示成一个二维的点。下边界表示横坐标,上边界表示纵坐标。