PostgreSQL索引(9) – BRIN
本文翻译自Egor Rogov的英文博客,且已征得Egor Rogov的同意。译者做了少量修改。
审校:纪昀红,中国人民大学信息学院在读博士生。
在前面几篇文章中,我们讨论了通用索引引擎、AM的接口和六种AM(Hash索引、B-tree索引、GiST索引、SP-GiST索引、GIN索引、RUM索引)。这篇文章将介绍BRIN索引。
1. 基本概念
和已经介绍过的索引不同,BRIN索引的思想是快速排除不满足查询条件的行,而不是快速找到匹配的行。它通常都是一个不精确的索引:它完全不包含基表中的TID。
BRIN更适合列值与物理位置相关的列。换句话说,即使一个查询没有order by子句,这个列的值也大致按升序或降序排列(这个列上没有索引)。
BRIN的一个重要特征是,它允许我们在表上创建一个很小的索引,仅增加很小的维护代价。
它的工作方式如下:表被划分成一些区间,每个区间包含一些页面(数据块)。它也因此而得名:Block Range Index,BRIN。索引存储了每个区间的摘要信息,通常来讲是这个区间的min和max值,也可能是其它信息。假如查询的包含一个列,并且这个查询的列值不会落入某个区间,则可以跳过整个区间。假如不能跳过,这个区间中的所有行都需要被扫描。
也可以说BRIN不是一个索引,只是索引扫描的加速器。我们可以把BRIN看作是对表进行分区的一种方式,把每个range是一个虚拟的分区。
2.结构
第0页是元页面。从第1页开始,连续N页(N取决于表的大小,并且可以增加)被称为revmap。recvmap之后,是摘要页面。
recvmap的数量与表的大小有关,如果持续向表中插入,recvmap不够用的时候,会向后扩展(占用一个摘要页面,该摘要页面的内容copy到索引的末尾)。
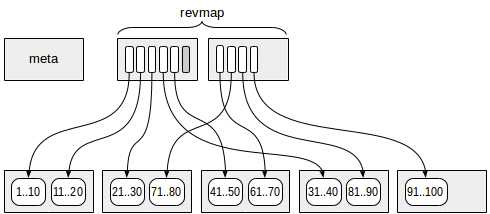
recvmap中有些并没有指向任何摘要页面,说明这些页面还没有摘要信息。
3. 扫描索引
如果索引没有保存指向基表的TID,这个索引如何被使用呢?它当然不能依次返回每个TID,但是它可以创建一个bitmap。bitmap页面有两种:精确的,指向基表具体的行;非精确的,指向基表的页面。BRIN使用的是非精确的bitmap。
扫描算法很简单。按顺序扫描所有的recv map(也就是说,按照基表中物理顺访问每个range)。指针指向每个摘要页面上的摘要。如果某个区间都不符合查询条件,则跳过整个区间。如果不能排除这个区间(或者没有摘要信息),这个区间内的所有页面都要被加入到bitmap中。这个位图,就像其它场景中的位图一样被使用。
4. 更新索引
更有意思的是,基表数据变化时,如何更新索引。
当向表中插入一行数据时,我们很容易确定它属于哪个区间,拿到这个区间的摘要信息。这都是一些简单的整数运算。假如,每个range包含4个页面,插入第13页插入42。range的编号是13/4=3,因此我们使用revmap中偏移为3的摘要信息。
这个区间中的最小值时31,最大值时40。插入的值是42,超出了这个区间,因此,需要更新最大值(见图片)。如果新插入的值仍然在现在的范围中,索引就不需要更新。
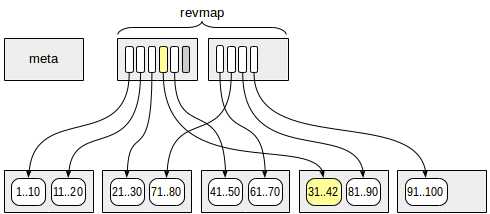
这些场景都是新插入的值所在的区间有摘要信息。创建索引时,会为所有可用的区间计算摘要信息,但是当这个表扩展时,新页面可能不在已有的range中。此时,可以有两种选择:
- 通常,索引不会立即更新。这不是一个大问题:就像已经提到的一样,扫描索引时,整个range都会被扫描。实际的update由vacuum完成,或者通过手工调用brin_summarize_new_values函数完成。
- 如果创建索引时指定了autosummarize参数,更新会立即完成。但是当向一个区间插入新值时,索引可能会被频繁更新,因此这个参数默认是关闭的。
当产生新的range时,revmap的体积会增加。任何时候,这个map都在元页面和摘要页面之间,需要去扩展一个新页面时,需要占用第一个摘要页面的空间,这个摘要页面的内容需要被移动到其它页面上。所以,rangemap永远在元页面和摘要页面中间。
当删除一行时,无需做任何事情。可以注意到,有时最小值或最大值会被删除,此时区间内值的上下界缩小了。但是检测这种情况,需要读取这个区间的所有值,代价太大。
即使不缩小上下界,索引的正确性也不会受到影响,但是扫描时,可能需要额外扫描一些区间。通常,可以对一个区间通过手工调用brin_desummarize_range和brin_summarize_new_values的方式重新计算摘要,我们如何自动检测是否需要呢?可是,没有很好的方法。
更新一行,仅仅是删除旧版本,并且添加一个新版本。
5. 示例
我们继续使用demo数据建立一个mini的数据仓库。假如为了BI报表,我们创建一个反范式化的表,用来表示从一个机场起降的航班,每行记录具体到每个座位。每个机场的航班每天导入一次,在该机场所在时区的午夜导入。数据不会被更新和删除。
表的模式为:
create table flights_bi(
airport_code char(3),
airport_coord point, -- geo coordinates of airport
airport_utc_offset interval, -- time zone
flight_no char(6), -- flight number
flight_type text. -- flight type: departure / arrival
scheduled_time timestamptz, -- scheduled departure/arrival time of flight
actual_time timestamptz, -- actual time of flight
aircraft_code char(3),
seat_no varchar(4), -- seat number
fare_conditions varchar(10), -- travel class
passenger_id varchar(20),
passenger_name text
);
我们可以使用程序模拟数据的导入,具体导入语句在此省略,读者如有兴趣,可以参考原文。
select count(*) from flights_bi;
count
----------
30517076
(1 row)
select pg_size_pretty(pg_total_relation_size('flights_bi'));
pg_size_pretty
----------------
4127 MB
(1 row)
我们共导入了3千万行数据,4GB。不是很大,但是作为示例已经足够了:扫描一次,大约需要10秒钟。
我们应该对哪些列建立索引呢?
我们已经提到,BRin索引适合数据与物理位置有相关性的列。PG的统计信息中已经包含这个值,被称作相关性。优化器使用这个值来从索引扫描和位图扫描中做选择。我们也可以使用它估计BRIN索引的适合程度。
上面的例子中,数据明显按天排序(scheduled_time,计划起降时间;或actual_time,实际起降时间)。这是因为,数据都是被追加进来的。没有更新和删除。
analyze flights_bi;
select attname, correlation from pg_stats where tablename='flights_bi'
order by correlation desc nulls last;
attname | correlation
--------------------+-------------
scheduled_time | 0.999994
actual_time | 0.999994
fare_conditions | 0.796719
flight_type | 0.495937
airport_utc_offset | 0.438443
aircraft_code | 0.172262
airport_code | 0.0543143
flight_no | 0.0121366
seat_no | 0.00568042
passenger_name | 0.0046387
passenger_id | -0.00281272
airport_coord |
(12 rows)
相关性的绝对值越接近于1,则相关性越强,越适合BRIN索引。
fare_condition和flight_type的相关性虽然也很强,但是他们的列的唯一值并不多,其实并不适合BRIn索引。fare_condition表示舱位,只有三种不同的值:Business、Comfort、Economy。flight_type只有两种不同的值:departure、arrival。这是一种假象,虽然他们的相关性指数很高,但是他们并适合建立BRIN索引,因为:实际上,几个相邻的页面上,这几个值一定都会出现,无法在一个连续的区间上排除任何值。
相关性可能会减弱
当数据改变时,一些字段的相关性可能很容易被削弱。这是由于PG的多版本控制原理导致的。一个页面的旧版本的行被删除之后,新版本的行可能会被插入到表中的任意空闲位置。因此,所有的行在更新之后,可能会被打的很乱。
我们可以通过减小fillfactor来缓解这个问题,因为这可以在页面上预留更多的空闲空间,供更新用。但是,我们真的想增加继续增加一个大表的体积吗?而且这没有解决delete导致的问题,删除数据之后,页面会释放一些空间,新插入数据时,可能就会插入到这些空闲空间中。如果没有删除,这些数据可能会被插入到文件的尾部。
顺便提一下,因为BRIN索引并不包含指向基表的TID,它没必要阻止HOT更新,但是它确实阻止了。
所以,BRIN索引主要为没有更新或很少更新的大表而设计的。这并不奇怪,因为它被设计的初衷,就是为了解决数据仓库中的数据分析问题,即它面向OLAP场景,而不是面向OLTP场景。
区间的大小如何选择?
当我们需要处理TB级别的表时,我们主要关心的是区间要选的合适,不能让BRIN索引的体积太大。
在我们的例子中,我们可以每天的数据占用多少页面:
select min(numblk), round(avg(numblk)) avg, max(numblk)
from (
select count(distinct (ctid::text::point)[0]) numblk
from flights_bi
group by scheduled_time::date
) t;
min | avg | max
------+------+------
1192 | 1500 | 1796
(1 row)
select relpages from pg_class where relname = 'flights_bi';
```
```
relpages
----------
528172
(1 row)
可以看到,每天的数据分布比较均匀。如果range的大小保持默认的128页,每天的数据占用9-14个页面。当查询某天的数据时,recheck阶段大约过滤掉10%的数据。
create index on flights_bi using brin(scheduled_time);
索引的大小仅仅为184 KB:
select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_idx'));
pg_size_pretty
----------------
184 kB
(1 row)
这种场景下,继续增大range的大小从而减小索引的体积并没有什么意义。反而是减小range的范围,提高精确度更有意义,当然索引的体积也会变大。
再看一下时区上的分布:
select airport_utc_offset, count(distinct (ctid::text::point)[0])/365 numblk
from flights_bi
group by airport_utc_offset
order by 2;
airport_utc_offset | numblk
--------------------+--------
12:00:00 | 6
06:00:00 | 8
02:00:00 | 10
11:00:00 | 13
08:00:00 | 28
09:00:00 | 29
10:00:00 | 40
04:00:00 | 47
07:00:00 | 110
05:00:00 | 231
03:00:00 | 932
(11 rows)
平均来讲,每个时区占用133个页面,但是分布缺非常不平均。默认的128页并不好,我们选择4个页面。
create index on flights_bi using brin(airport_utc_offset) with (pages_per_range=4);
select pg_size_pretty(pg_total_relation_size('flights_bi_airport_utc_offset_idx'));
pg_size_pretty
----------------
6528 kB
(1 row)
6. 执行计划
下面看一下索引是如何工作的,假如需要查询过去一周的数据:
set d 'bookings.now()::date - interval \'7 days\''
explain (costs off,analyze)
select *
from flights_bi
where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on flights_bi (actual time=10.282..94.328 rows=83954 loops=1)
Recheck Cond: ...
Rows Removed by Index Recheck: 12045
Heap Blocks: lossy=1664
-> Bitmap Index Scan on flights_bi_scheduled_time_idx
(actual time=3.013..3.013 rows=16640 loops=1)
Index Cond: ...
Planning time: 0.375 ms
Execution time: 97.805 ms
可以看到,优化器使用了索引。所以到底有多精确呢?最终符合条件的行数占索引返回的行数的比例可以说明。本例中为83954 / (83954 + 12045),大约为90%,和期望的一样。
16640这个数字是从哪里来的呢?这是因为优化器构造了一个非精确的位图,它假设每个页面有10行数据,一共选出了1664页,所以优化器认为有16640行。。。这是一个瞎猜的数据,不要关心它。
几个BRIN索引可以被同时适用。例如:
set d 'bookings.now()::date - interval \'60 days\''
explain (costs off,analyze)
select *
from flights_bi
where scheduled_time >= :d and scheduled_time < :d + interval '30 days'
and airport_utc_offset = interval '8 hours';
QUERY PLAN
---------------------------------------------------------------------------------
Bitmap Heap Scan on flights_bi (actual time=62.046..113.849 rows=48154 loops=1)
Recheck Cond: ...
Rows Removed by Index Recheck: 18856
Heap Blocks: lossy=1152
-> BitmapAnd (actual time=61.777..61.777 rows=0 loops=1)
-> Bitmap Index Scan on flights_bi_scheduled_time_idx
(actual time=5.490..5.490 rows=435200 loops=1)
Index Cond: ...
-> Bitmap Index Scan on flights_bi_airport_utc_offset_idx
(actual time=55.068..55.068 rows=133800 loops=1)
Index Cond: ...
Planning time: 0.408 ms
Execution time: 115.475 ms
与B-tree的比较
如果我们在同样的字段上创建B-tree索引呢?
create index flights_bi_scheduled_time_btree on flights_bi(scheduled_time);
select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_btree'));
pg_size_pretty
----------------
654 MB
(1 row)
看起来索引的体积比BRIN大上千倍,但是它的执行速度要快一点:优化器根据统计信息已经知道数据已经按物理顺序排序,不需要构建位图,而且,不需要recheck索引条件。
explain (costs off,analyze)
select *
from flights_bi
where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN
----------------------------------------------------------------
Index Scan using flights_bi_scheduled_time_btree on flights_bi
(actual time=0.099..79.416 rows=83954 loops=1)
Index Cond: ...
Planning time: 0.500 ms
Execution time: 85.044 ms
这就是BRIN索引的魅力所在,虽然精确度不高,但是可以极大的节省空间。
7. 操作符类
minmax
对可以比较大小的数据类型来说,摘要信息包括最大值和最小值。相应操作符类的名字中包含minmax,例如date_minmax_ops。实际上,我们到现在为止使用的数据类型都属于这一类,大多数也属于这一类。
inclusive
不是所有的操作符都支持比较。例如,point类型就没有。这就是一列上没有相关性统计信息的原因。
select attname, correlation
from pg_stats
where tablename='flights_bi' and attname = 'airport_coord';
attname | correlation
---------------+-------------
airport_coord |
(1 row)
大多数这种数据类型都涉及一个概念:边界区域。例如,一个地理形状的边界区域。我们已经在GiST索引中详细的讨论过这个特性。类似地,BRIN允许在这种数据类型上收集摘要信息:range内的所有值的边界区域就是摘要信息。
和GiST索引不同的是,BRIN摘要信息的类型必须和列值的类型相同。因此,我们不能为point类型建立BRIN索引。但是可以把point转成box,同时让一个range仅包含一个页面:
create index on flights_bi using brin (box(airport_coord)) with (pages_per_range=1);
在这种极端场景下,索引的体积也只有30MB:
select pg_size_pretty(pg_total_relation_size('flights_bi_box_idx'));
pg_size_pretty
----------------
30 MB
(1 row)
索引查询机场信息:
select airport_code, airport_name
from airports
where box(coordinates) <@ box '120,40,140,50';
airport_code | airport_name
--------------+-----------------
KHV | Khabarovsk-Novyi
VVO | Vladivostok
(2 rows)
但是优化器拒绝使用这个索引:
analyze flights_bi;
explain select * from flights_bi
where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN
---------------------------------------------------------------------
Seq Scan on flights_bi (cost=0.00..985928.14 rows=30517 width=111)
Filter: (box(airport_coord) <@ '(140,50),(120,40)'::box)
禁止顺序扫描,再看一下:
set enable_seqscan = off;
explain select * from flights_bi
where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on flights_bi (cost=14079.67..1000007.81 rows=30517 width=111)
Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
-> Bitmap Index Scan on flights_bi_box_idx
(cost=0.00..14072.04 rows=30517076 width=0)
Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
虽然可以使用索引,但是优化器认为需要在整个表上建立位图索引(Bitmap Index Scan节点中的rows),这是优化器选择顺序扫描的原因。发生这种现象的原因是:PG没有手机地理数据类型的统计信息,优化器一直在瞎算代价:
select * from pg_stats where tablename = 'flights_bi_box_idx';
-[ RECORD 1 ]----------+-------------------
schemaname | bookings
tablename | flights_bi_box_idx
attname | box
inherited | f
null_frac | 0
avg_width | 32
n_distinct | 0
most_common_vals |
most_common_freqs |
histogram_bounds |
correlation |
most_common_elems |
most_common_elem_freqs |
elem_count_histogram |
虽然是这样,但是索引仍然可以正常工作:
explain (costs off,analyze)
select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN
----------------------------------------------------------------------------------
Bitmap Heap Scan on flights_bi (actual time=158.142..315.445 rows=781790 loops=1)
Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Rows Removed by Index Recheck: 70726
Heap Blocks: lossy=14772
-> Bitmap Index Scan on flights_bi_box_idx
(actual time=158.083..158.083 rows=147720 loops=1)
Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Planning time: 0.137 ms
Execution time: 340.593 ms
这说明,关键的时刻,还是需要PostGIS,因为它可以收集统计信息。
8. 内部结构
使用pageinspect插件就可以查看BRIN索引的内部结构。首先查看range的大小,和recvmap中页面的数量:
select *
from brin_metapage_info(get_raw_page('flights_bi_scheduled_time_idx',0));
magic | version | pagesperrange | lastrevmappage
------------+---------+---------------+----------------
0xA8109CFA | 1 | 128 | 3
(1 row)
第0页为元页面,第1-3页是revmap页面,其它页面是摘要页面。从revmap页面可以找到每个range对应摘要信息的引用。下面是第一个range的信息,对应表中前128个页面:
select *
from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1))
limit 1;
pages
---------
(6,197)
(1 row)
select allnulls, hasnulls, value
from brin_page_items(
get_raw_page('flights_bi_scheduled_time_idx',6),
'flights_bi_scheduled_time_idx'
)
where itemoffset = 197;
allnulls | hasnulls | value
----------+----------+----------------------------------------------------
f | f | {2016-08-15 02:45:00+03 .. 2016-08-15 17:15:00+03}
(1 row)
下一个range:
select *
from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1))
offset 1 limit 1;
pages
---------
(6,198)
(1 row)
select allnulls, hasnulls, value
from brin_page_items(
get_raw_page('flights_bi_scheduled_time_idx',6),
'flights_bi_scheduled_time_idx'
)
where itemoffset = 198;
allnulls | hasnulls | value
----------+----------+----------------------------------------------------
f | f | {2016-08-15 06:00:00+03 .. 2016-08-15 18:55:00+03}
(1 row)
对inclusion操作符类来说,value字段显示如下:
{(94.4005966186523,69.3110961914062),(77.6600036621,51.6693992614746) .. f .. f}
第一个值时嵌入的矩形,f字母表示空元素和不合并的值。目前只有IPv4和IPv6地址是不可合并的。
9. 属性
第二篇文章已经提供了查询这种属性的查询。
AM层面的属性:
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
brin | can_order | f
brin | can_unique | f
brin | can_multi_col | t
brin | can_exclude | f
索引层面的属性:
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | f
bitmap_scan | t
backward_scan | f
它只支持位图扫描。
BRIN索引不支持cluster。我们会持有一张大表的Exclusive锁做cluster吗?没准在cluster的过程中,磁盘就被耗尽了。
列层面的属性:
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | f
search_array | f
search_nulls | t
唯一有价值的属性就是,它可以操作NULL值。